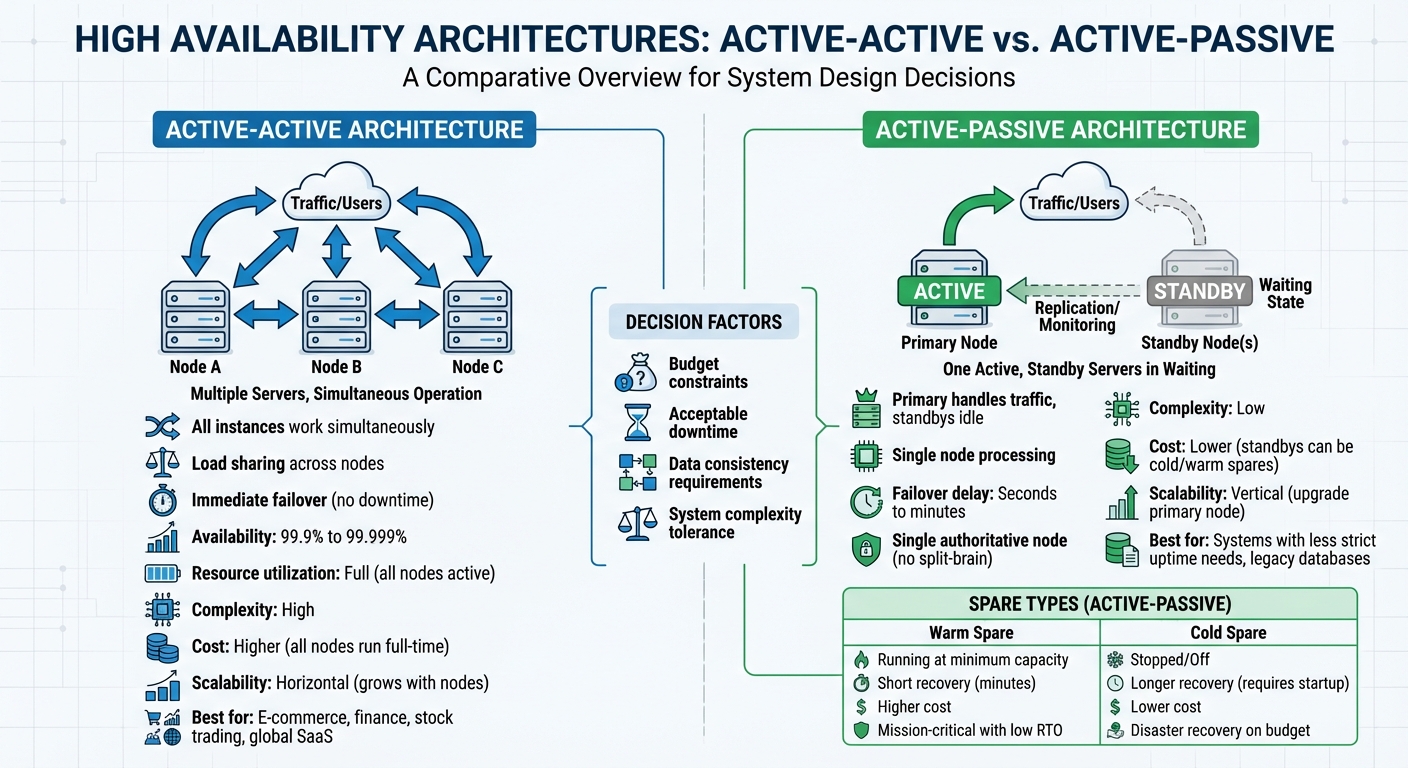
High availability (HA) ensures systems stay online with minimal downtime, critical in today's 24/7 digital world. The two main approaches to HA are Active-Active and Active-Passive architectures. Here's a quick breakdown:
- Active-Active: Multiple instances work simultaneously, sharing the load. This setup ensures no downtime during failover but is more complex and costly to implement.
- Active-Passive: A primary instance handles traffic while standby instances remain idle until needed. It's simpler and cost-effective but involves a brief delay during failover.
Key differences:
- Active-Active: Maximizes uptime and performance, ideal for industries like e-commerce or finance where interruptions are costly.
- Active-Passive: Focuses on reliability and cost efficiency, better suited for systems with less strict uptime needs.
Both options reduce single points of failure, but the choice depends on your budget, uptime requirements, and system complexity.
Active-Active vs Active-Passive Architecture Comparison
15. Design High Availability & Resilience System, HLD | Active Passive & Active Active Architecture
sbb-itb-01010c0
1. Active-Active Architecture
An active-active setup runs multiple identical instances simultaneously across different failure domains, ensuring there’s no single point of failure. If one instance goes down, others immediately take over without disrupting service. This seamless failover keeps operations running smoothly and without interruptions.
As outlined in Microsoft's Azure Well-Architected Framework:
Active-active deployments maximize service availability by running multiple instances of a workload simultaneously, each actively handling traffic. This setup ensures immediate failover, eliminates downtime, and optimizes resource use.
This configuration is the foundation for creating systems with strong redundancy and fault tolerance.
Redundancy and Fault Tolerance
Active-active architectures establish redundancy at multiple levels: Pod level (leveraging Kubernetes ReplicaSets), Node level (spanning Availability Zones), and Cluster level (deploying across multiple regions). Tools like Azure Front Door and AWS Route 53 play a critical role here, monitoring endpoint health and rerouting traffic to functional instances - often within seconds.
To manage sudden traffic surges or regional failures, Horizontal and Cluster Autoscalers step in, dynamically increasing capacity in healthy regions to maintain performance. The N+1 redundancy model ensures there’s always extra capacity available to handle a node failure without affecting performance. This design supports availability levels ranging from 99.9% to 99.999%.
Performance and Scalability
Active-active configurations are highly efficient because all instances are actively utilized. By routing users to the server closest to their location (geoproximity routing), latency is reduced significantly. When traffic spikes or a failure occurs, the architecture scales horizontally by redistributing the load across operational nodes.
The "Deployment Stamps" pattern enhances scalability further. Instead of adding individual servers, it replicates entire self-contained units, complete with compute, storage, and networking resources. This method allows for seamless horizontal scaling across regions while ensuring consistent performance.
Implementation Complexity
One of the biggest hurdles in active-active setups is maintaining data consistency. A "split-brain" scenario, where different nodes mistakenly believe they are the primary source of truth, must be avoided. To achieve this, the compute layer is designed to remain stateless, so any node can handle any request without relying on local session data.
Consistency methods like synchronous replication ensure accuracy but can slow down writes, while asynchronous replication introduces delays in data updates. Network partitions complicate things further, but using a quorum or witness node (with an odd number of nodes) helps the system make majority decisions even when communication between nodes is disrupted. Managed services like Azure Cosmos DB simplify some of these complexities, but the operational demands of active-active setups remain higher compared to simpler architectures.
2. Active-Passive Architecture
In an active-passive setup, a primary node manages all traffic while standby nodes remain idle, ready to take over in case of failure. This configuration, often referred to as "2N" redundancy, pairs an active node with a standby node to eliminate single points of failure without the added complexity of managing multiple active nodes.
As described in Microsoft's Azure Well-Architected Framework:
Active-passive deployment configurations provide a cost-effective way to ensure DR by running a primary instance that handles all traffic while keeping secondary instances idle but ready.
This model emphasizes simplicity and cost efficiency, prioritizing these factors over the continuous availability offered by active-active setups.
Redundancy and Fault Tolerance
Active-passive architecture relies on heartbeat monitoring to keep tabs on the primary node's health. If the heartbeat fails, automated systems promote the standby node, ensuring continuity. Data replication can be synchronous - minimizing data loss - or asynchronous - favoring performance.
A key advantage of this setup is its single authoritative node, which simplifies state management and avoids multi-master conflicts. This eliminates the risk of a split-brain scenario, where nodes might operate independently and inconsistently. Centralizing the system state on one node also makes troubleshooting more straightforward.
That said, the trade-off here is that failover isn't instantaneous. It typically takes seconds to minutes for the standby node to activate and for traffic to reroute. During this time, user sessions are often disrupted, forcing users to log back in unless session states are stored externally.
Performance and Scalability
Unlike active-active setups, which distribute processing across multiple nodes, active-passive relies on a single active node. This means performance is limited by the capacity of that primary node. While some passive nodes can handle read-only traffic, all write operations are centralized, further constraining scalability.
When traffic increases, scaling in an active-passive model involves upgrading the primary node rather than spreading the load across multiple active nodes. This makes it less flexible in handling sudden spikes in demand compared to active-active configurations.
Cost Efficiency
Where active-passive truly stands out is in its cost-effectiveness. Standby nodes act as a safety net, sitting idle until they're needed. Depending on your requirements, you can choose between warm spares - which run at minimal capacity - or cold spares, which remain completely offline until activated.
| Feature | Warm Spare | Cold Spare |
|---|---|---|
| Status | Running at minimum capacity | Stopped/Off |
| Recovery Time | Short (minutes) | Longer (requires startup) |
| Cost | Higher (ongoing compute costs) | Lower (storage costs only) |
| Best Use Case | Mission-critical with low RTO | Disaster recovery on a budget |
Cold spares are the most affordable option but have longer recovery times since resources need to start up before failover. Warm spares, on the other hand, strike a balance between cost and recovery speed, making them a good choice for workloads that can handle brief interruptions but don't justify the expense of active-active setups.
Implementation Complexity
Compared to active-active architectures, active-passive is much simpler to implement. With only one node handling data writes at any given time, you avoid the headaches of consistency issues and complicated state synchronization. This centralized design makes it easier to predict system behavior and diagnose problems.
For high-availability singleton clusters, both nodes need shared storage (e.g., NFS) to access critical configurations and logs during failover. To safeguard redundancy layers, apply resource locks like Azure's "CanNotDelete" protection on key components, such as load balancers, to prevent accidental deletion. Regular chaos drills can help ensure your failover process meets the desired recovery time objective (RTO).
Advantages and Disadvantages
Choosing between active-active and active-passive setups often boils down to a trade-off between uninterrupted service and operational simplicity. Active-active architectures are designed for continuous uptime, ensuring near-instant failover with no service disruption since all nodes are online and actively sharing the workload. On the other hand, active-passive configurations may experience a short delay - ranging from seconds to minutes - during failover as the standby node is promoted. This highlights the balance between performance and simplicity.
Active-active systems excel at distributing traffic evenly, which eliminates bottlenecks caused by single-node limitations and supports horizontal scaling. In contrast, active-passive setups rely on a single active node to handle the load, which inherently limits performance and scalability.
The complexity of these systems is another key factor. Active-active configurations require advanced mechanisms for data synchronization and conflict resolution across multiple active nodes, making them more challenging and expensive to implement and maintain. Active-passive systems, however, operate with a single authoritative node, avoiding the synchronization headaches of multi-master systems. This simplicity makes them especially appealing in fields like finance and healthcare, where maintaining data integrity is non-negotiable.
| Feature | Active-Active | Active-Passive |
|---|---|---|
| Redundancy | Immediate; no service disruption | Minor delay during failover |
| Performance | Load balanced across all nodes | Limited by single active node |
| Scalability | Grows with additional nodes | Standby nodes don't add throughput |
| Cost | Higher; all nodes run full-time | Lower; standby nodes can be idle |
| Complexity | High; requires strong synchronization | Low; single authoritative writer |
| Resource Efficiency | Full utilization of resources | Standby capacity serves as insurance |
For mission-critical systems like stock trading platforms, active-active is the go-to choice because it minimizes downtime to virtually zero. Meanwhile, applications with less stringent uptime requirements often lean toward active-passive setups for their cost-effective simplicity.
Conclusion
When deciding on a high availability strategy, it’s essential to weigh factors like acceptable downtime, budget constraints, and the complexity of synchronization. Each approach comes with its own set of trade-offs. For example, active-active architectures excel at distributing workloads across all nodes, making them a go-to choice for global SaaS platforms, e-commerce websites, and stock trading systems - industries where even a brief downtime can lead to revenue losses. On the other hand, active-passive setups focus on strict data consistency by relying on a single authoritative node.
"Active-active is superior when continuous uptime and load sharing are important... Active-passive, meanwhile, prioritizes reliability with a streamlined primary/standby setup." – Aerospike
While active-active systems demand all nodes to operate at full capacity - resulting in higher infrastructure costs - active-passive configurations can save costs by utilizing cold spares or minimal standby resources. For businesses with legacy databases that don’t support multi-master writes, active-passive remains a practical and reliable option. These considerations are crucial in crafting an architecture that aligns with both technical and business objectives.
The B2B Ecosystem offers consulting services to help you navigate these decisions. From evaluating your uptime needs to defining key metrics like Recovery Time Objective (RTO) and Recovery Point Objective (RPO), their experts can guide you toward implementing the high availability pattern that best suits your goals. With professional insights, you can effectively balance cost, complexity, and reliability, ensuring your infrastructure supports your business priorities.
FAQs
What’s the difference between active-active and active-passive architectures?
The main distinction between active-active and active-passive architectures lies in how they distribute workloads and manage failover situations.
In an active-active setup, multiple nodes operate simultaneously, sharing the workload evenly. This approach helps maintain high performance, ensures continuous availability, and reduces downtime to a minimum.
On the other hand, an active-passive architecture relies on a primary node and a standby node. The standby remains idle until the primary node encounters an issue, at which point it steps in to take over. While this method is simpler and often more budget-friendly, it may lead to brief delays during the failover process.
Active-active setups are best suited for systems demanding uninterrupted uptime and peak performance. Meanwhile, active-passive configurations are a better fit for scenarios where simplicity and cost efficiency outweigh the need for instant failover.
How does an active-active architecture ensure data consistency and prevent split-brain issues?
An active-active architecture keeps data consistent by synchronizing it across multiple active nodes or regions in real time. To achieve this, it relies on tools like conflict resolution protocols and distributed consensus algorithms, which help prevent discrepancies and ensure the system remains dependable.
To address potential split-brain scenarios - where nodes lose communication and start working independently - active-active setups use safeguards like quorum-based decision-making or automated failover mechanisms. These measures ensure that only one group of nodes serves as the authoritative source during network partitioning, preserving system integrity and reducing disruptions.
What are the benefits of choosing an active-passive architecture over an active-active setup?
An active-passive architecture is a go-to choice for businesses aiming to keep expenses in check while maintaining simplicity. In this setup, standby nodes stay idle until they're required, which helps save on resources and keeps operational demands low.
This setup works well for organizations that need high availability but don’t have workloads demanding continuous synchronization between multiple active nodes. Plus, it’s easier to manage compared to the more demanding active-active configuration.


